试管5自由度识别说明文档
简介
试管5轴识别方法为双目摄像头与深度学习视觉识别网络结合。摄像头采用英特尔D435深度摄像头,可获取RGB-D图;视觉识别使用YOLOv8-seg模型。最终可获得试管的三维空间位置、试管朝向与俯仰角度共5自由度的空间信息。整体流程如下图:
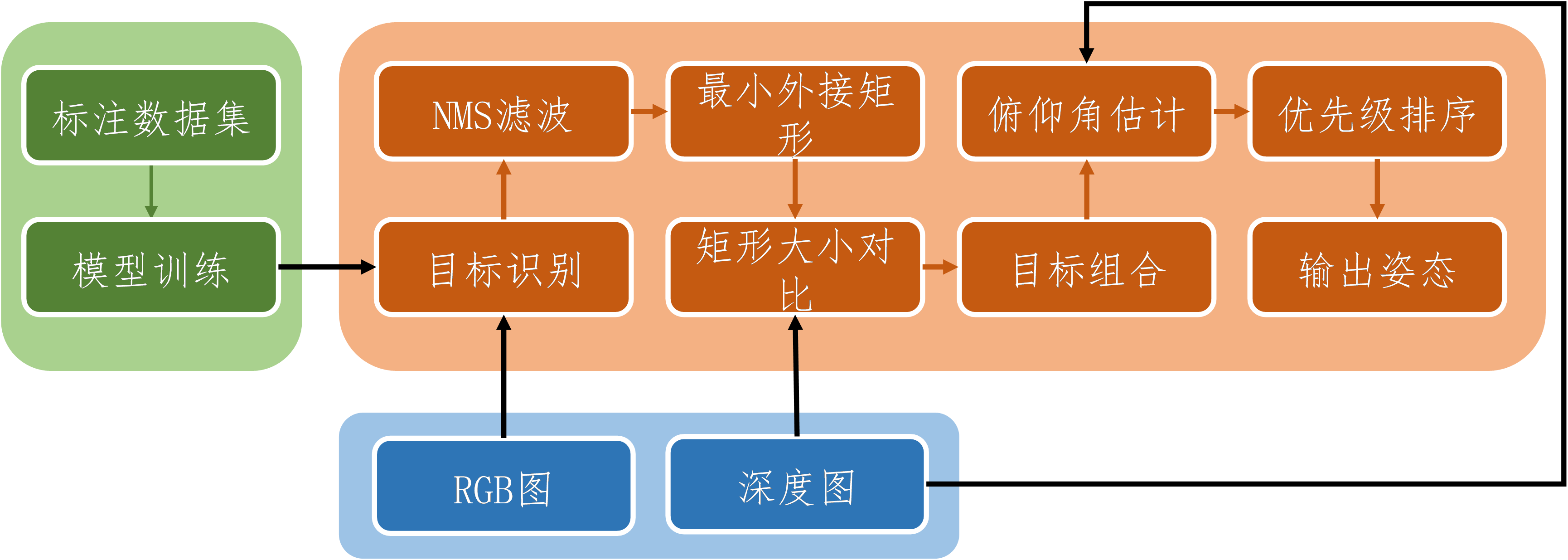
深度学习模型
YOLOv8-seg是一种基于目标检测和语义分割的实例分割方法。但在一个模型中,一个像素或像素块只能属于一种类别,而计算姿态需要不同试管与试管盖之间的归属关系,即判断试管盖出自哪个试管。识别过程中将运行两个模型,分别用于获取试管整体与试管盖的掩膜坐标。
准备数据集
数据集使用Roboflow平台准备,将包含试管的图片上传后标注,生成包裹试管盖或试管的多边形,最后以yolov8格式导出
上传原始图片
标注数据
如图下所示,使用smart polygon工具进行多边形预分割,后续手动再调整预分割出的多边形:

导出数据集
如图3所示,在preprocessiong中选择auto-orint。并把分辨率resize成640×640分辨率,在modify classes中选择要训练的模型的识别对象。
导出格式选择YOLOv8,如图4所示:
模型训练
模型训练建议使用20系及以上显卡,16系显卡会出现训练loss为Nan的问题。超参数可使用默认参数,关闭patience功能,固定训练800轮。 可使用autoDL云计算平台租用GPU,选择官方基础镜像中的PyTorch=1.11版本。使用SSH连接服务器,filezilla上传文件。使用pip install ultralytics安装yolo。将数据集dataset上传到auto-tmp(挂载高性能盘)文件夹下。开启学术资源加速可使服务器访问github
模型推理
模型输入源是摄像头捕获的RGB图像,不包含深度信息。模型输出包括所检测目标的多边形掩膜像素坐标及置信度。
数据后处理
非极大值抑制(NMS)滤波
在实际使用时,单个物体往往会产生多个冗余的预测框与掩膜,但用于计算仅需一个物体只对应一个预测框与掩膜。通过NMS滤波可以删除冗余的结果,将检出对象减小为1个。
具体流程为从所有框中选出置信度最大的候选框,并删除其它面积重合程度超过阈值(交并比,IoU,设置为0.6)的候选,最后去除选出的置信度最大的候选框之后重复该步骤。
最小外接矩形
需对模型预测得到的多边形掩膜进行处理,并提取出有效信息。通过RGB图像,应提取出试管像素位置与试管朝向角。多边形掩膜应是无论是试管盖或试管,都可视为矩形,通过计算掩膜的最小外接矩形,可获得目标的朝向(不分前后,范围是180度)及中心坐标。并且通过计算掩膜面积与外接矩形面积比值,可判断目标是否被局部遮挡,目标识别是否完整,可作为是否正确识别物体的另一个判断标准。
最小外接矩形可使用openCV中的minAreaRect函数获得,如图5所示,得到矩形的长宽、中心点坐标、旋转角度。后续数据处理在最小外接矩形的基础上进行。

矩形大小对比
根据目标像素坐标,可从RGB-D中得到对应点的目标深度。经过换算可得到目标的三维位置。如式(1)所示。 $$ \left{\begin{array}{l} X=\left(x-c_x\right) \cdot d / f_x \ Y=-\left(y-c_y\right) \cdot d / f_y \ Z=d \end{array}\right. $$
其中(X,Y,Z)表示像素点在相机坐标系中的空间位置,c_x,c_y,f_x,f_y分别表示相机的光心坐标与焦距,并且f_x=f_y,d表示通过双目相机识别到的深度。
由于同一深度对应矩形大小相同,可将检测目标矩形大小与实际物体应当的大小对比,用于检测目标是否正确,以及深度是否合理。如式(2)所示为获取正常试管像素大小的公式:
其中w_t,h_t分别是试管或试管盖的实际宽度与长度,w_e,h_e分别是深度d下该目标在图片中的期望像素宽度与像素长度。 得到期望像素的尺寸后,可结合检测到的最小外接矩形得到形状置信度,形状置信度conf的计算公式如式(3)所示:
其中r_h,r_w,r_b分别是期望矩形与检出的外接矩形的高度的比、宽度的比、以及多边形面积S_poly与最小外接矩形面积S_rect的比。T_h,T_w,T_b为各自的阈值。对于试管盖,阈值都为0.7;对于试管,阈值分别为0.7、0.7、0.5。
目标组合
检测试管与试管盖分别由两个YOLOv8-seg完成,需判断两者目标是否属于同一个试管。方法是判断试管盖外接矩形中心在哪个试管外接矩形内部,并将两者组合成一个试管对象。
俯仰角估计
提取组合对象中试管盖与试管中心的深度,利用深度差估算俯仰角如图3所示,具体公式如式(4)所示:
其中φ表示试管的俯仰角,d_d表示试管中心点与试管盖中心点的深度差,d_l表示试管中心点与试管盖中心点的水平距离。
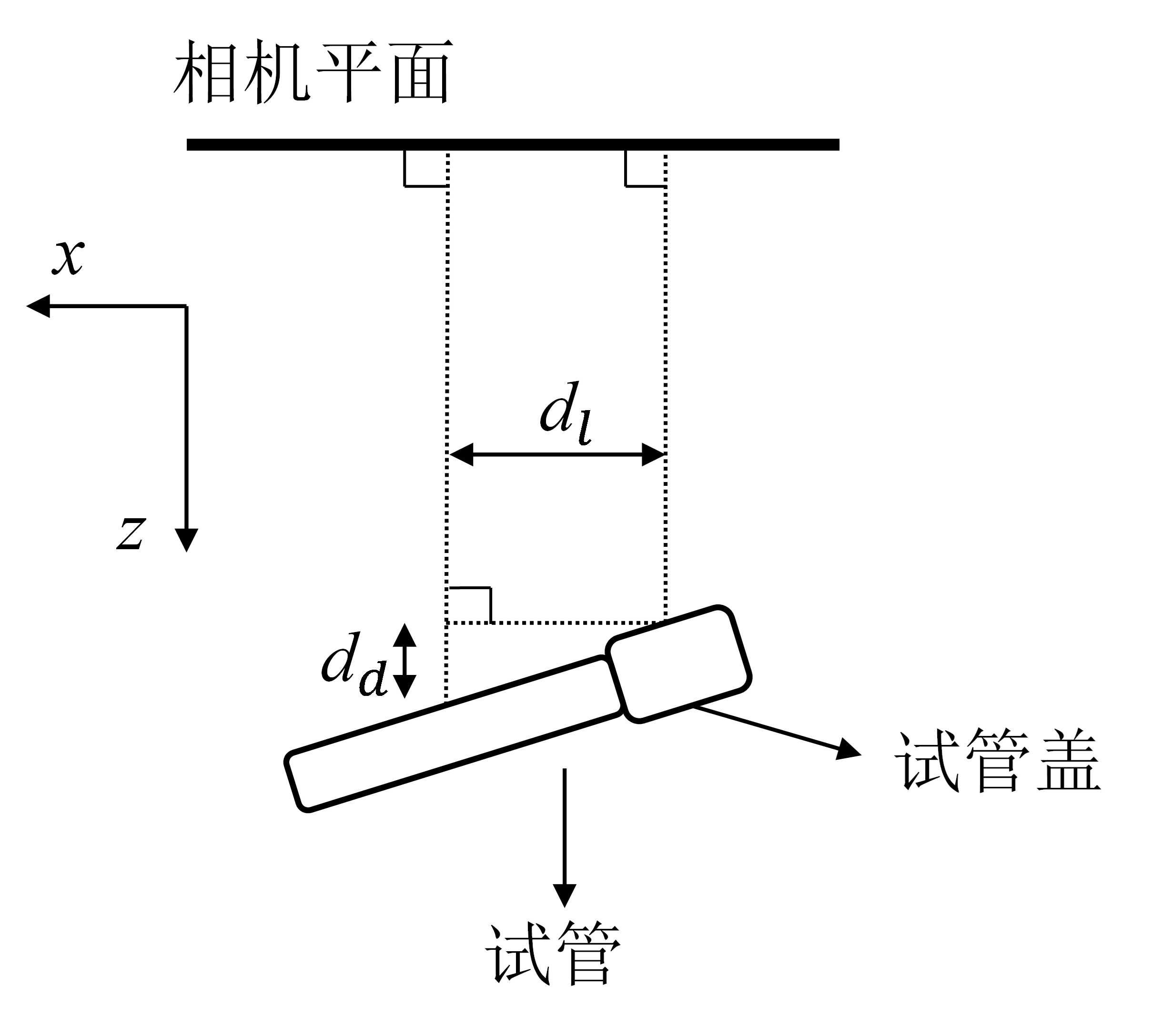
由于双目深度相机在640*480分辨率下的深度分辨率仅有1mm精度,导致俯仰角精度较差,因此通过读取5帧数据深度再平均的方式减小深度误差。
优先级排序
首先从试管对象中选择俯仰角小于30度的试管,再依据离相机的距离进行排序。选择离相机中心点最近的试管为抓取对象。